“Toronto has a large unhoused population. Freezing winters mean it is critical there are enough places in shelters. We are interested to understand how usage of shelters changes in colder months, compared with warmer months.
We use data provided by the City of Toronto about Toronto shelter bed occupancy. Specifically, at 4 a.m. each night a count is made of the occupied beds. We are interested in averaging this over the month. We cleaned, tidied, and analyzed the dataset using the statistical programming language R as well as the tidyverse, janitor, opendatatoronto, lubridate, and knitr. We then made a table of the average number of occupied beds each night for each month.
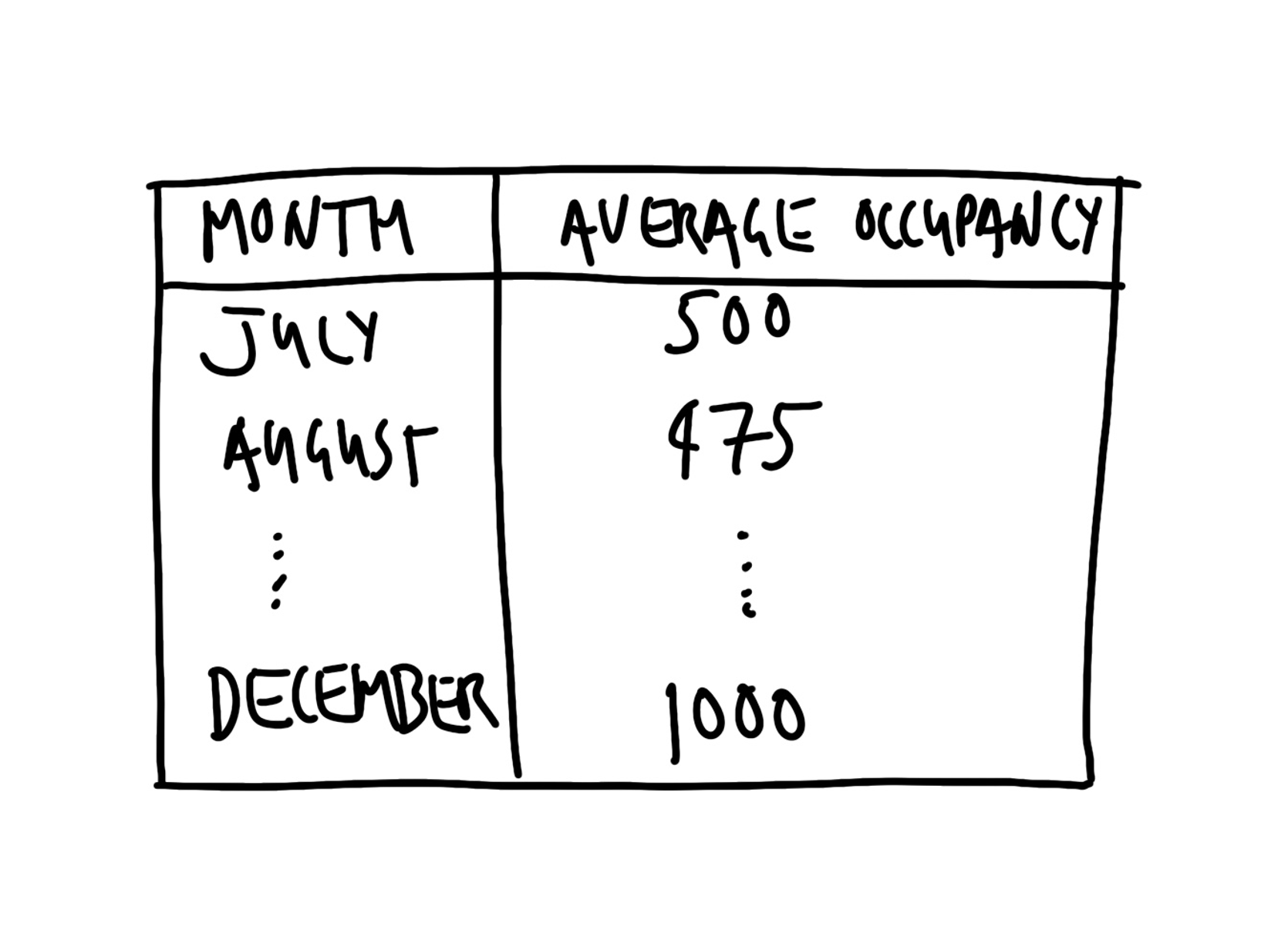
We found that the daily average number of occupied beds was higher in December 2021 than July 2021, with 34 occupied beds in December, compared with 30 in July. More generally, there was a steady increase in the daily average number of occupied beds between July and December, with a slight overall increase each month.”